JDK源码阅读笔记之LinkedList
前言
对大部分需求来说,ArrayList就能满足我们的需求,但是LinkedList和ArrayList的区别是什么,他内部的实现是什么样的,需要我们去搞清楚,才能对两者进行恰当的使用。
LinkedList的概述:
- LinkedList本质上是一个双向列表,虽然他没有这么叫。他不仅仅实现了List接口,同时还实现了Deque接口。
- LinkedList允许null元素。
- LinkedList是线程不安全的,在多线程环境下修改LinkedList的结构要在外部加锁。
- 可以使用Collections的synchronizedList方法来包装LinkedList,实现线程安全性。
- LinedList对插入删除操作的时间复杂度是O(1),但是对查找非首尾的时间复杂度是O(n)。
LinkedList的属性:
LinkedList一共有三个属性:
- size:表示LinkedList的当前大小
- first:表示头节点
- last:表示尾节点
LinkedList的方法:
LinkedList的所有public方法如下图,下面我们来通过源码解释来了解他们
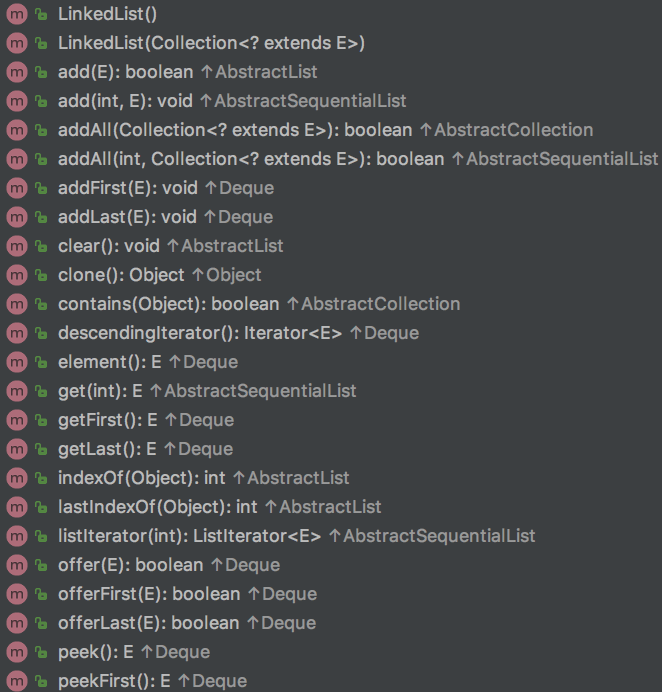
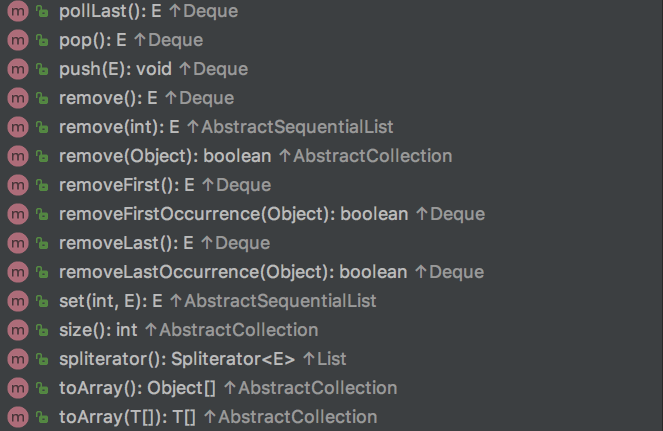
构造方法:
- LinkedList():
public LinkedList() {
}
这个构造方法初始化了一个空的LinkedList对象。
2. LinkedList(Collection<? extends E>)
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
通过内部的addAll方法将传入的集合对象的元素加入到LinkList中,addAll方法的时间复杂度是O(n)。详情请看addAll方法。
其他方法:
1.add(E e)
public boolean add(E e) {
linkLast(e);
return true;
}
add方法用来向LinkedList中添加元素,接受一个范型的参数,通过默认的linkLast方法对元素e进行操作。
void linkLast(E e) {
final Node<E> l = last; // 保存之前的last元素
final Node<E> newNode = new Node<>(l, e, null); // 创建新的节点,他的前置节点是之前的last节点
last = newNode; // 将新节点赋给last节点
if (l == null) // 如果之前的last节点是null 说明是一个空LinkedList
first = newNode; // 这时候头节点也应该指向新节点(整个LinkedList中只有一个元素)
else
l.next = newNode; // 不是空LinkedList,将之前的last节点节点的后置节点变为新节点
size++; // 整个LinkedList的大小加1
modCount++; // 操作标示加1
}
2.add(int index, E element):
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
将一个元素插入到指定的位置。首先会对插入的校验是否合法,然后如果是插入的最后位置,调用linkLast方法(详情见构造方法2),其他位置先调用node方法,获取对应位置的节点,然后调用linkBefore方法插入。
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
checkPositionIndex方法index是不是大于0小于LinkedList的size。不是的话,就会抛出IndexOutOfBoundsException异常。
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) { // 判断index是否小于size / 2。使用右移一位提高计算效率。
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
node方法对节点进行查找。用到了二分查找的思想来节约时间,小于size/2从头开始查找,大于size/2从尾开始查找。
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev; // 获取插入位置的前置节点
final Node<E> newNode = new Node<>(pred, e, succ); // 创建新节点,并关联前置和后置节点
succ.prev = newNode; // 将插入位置置为新节点
if (pred == null) // 前置节点是null,为空LinkedList
first = newNode; // 头节点指向新节点
else
pred.next = newNode; // 前置节点下一个元素指向新节点
size++; // size + 1
modCount++; // 操作标示 + 1
}
前置插入代码如上。
3.addAll(Collection<? extends E> c)
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
addAll(Collection<? extends E> c)是addAll(int index, Collection<? extends E> c)方法的重载方法。当在末尾插入元素的时候就等同addAll(Collection<? extends E> c)方法。
4.addAll(int index, Collection<? extends E> c):
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index); // 检查是否越界
Object[] a = c.toArray(); //把插入集合转成数组 如果集合c是null,那么就会触发NullPointerException
int numNew = a.length;
if (numNew == 0) // 没有元素可以插入 return failse。未变更LinkedList
return false;
Node<E> pred, succ; // 声明前置和后置节点
if (index == size) { // 如果插入位置是末尾 前置元素就是last,后置元素是null
succ = null;
pred = last;
} else {
succ = node(index); // 中间插入,首先找到插入位置节点,赋值给succ。前置节点赋值给pred。
pred = succ.prev;
}
//开始循环插入
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null); // 初始化新节点,前置节点设为pred
if (pred == null) // 空LinkedList 头节点也设为新节点
first = newNode;
else
pred.next = newNode; // pred后置节点关联新节点
pred = newNode; // pred设为新节点,继续下一轮循环。
}
if (succ == null) { // 空LinkedList或从最后一个节点插入, 尾节点也设为插入的最后节点
last = pred;
} else {
pred.next = succ; // 插入的最后节点的后置节点和succ互相关联
succ.prev = pred;
}
size += numNew; // size增加
modCount++; // 操作标示增加
return true;
}
指定位置插入整个集合到LinkedList中,将插入位置和后面的元素全部右移,时间复杂度是O(n)。
5.addFirst(E e)
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f); // 初始化新节点,并将后置节点设为头节点
first = newNode; // 新节点变为头节点
if (f == null) // 旧头节点是null,LinkedList是空
last = newNode; // 尾节点也设为新节点
else
f.prev = newNode; // 旧头节点的前置节点设为新节点
size++;
modCount++;
}
就是将新元素插入到LinkedList头部。内部调用的是linkFirst方法来实现插入逻辑。
6.addLast(E e)
addLast方法将元素插入到LinkedList最后,方法等同于add(E e)。详细代码见add方法。
7.clear()
public void clear() {
// Clearing all of the links between nodes is "unnecessary", but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
将LinkedList里面的元素清空。逻辑上就是将所有的引用都变为null。下次gc的时候就被回收了。时间复杂度是O(n)
8.clone()
public Object clone() {
LinkedList<E> clone = superClone();
// Put clone into "virgin" state
clone.first = clone.last = null;
clone.size = 0;
clone.modCount = 0;
// Initialize clone with our elements
for (Node<E> x = first; x != null; x = x.next)
clone.add(x.item);
return clone;
}
private LinkedList<E> superClone() {
try {
return (LinkedList<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
对LinkedList进行克隆。从代码可以看出只是对LinkedList本身进行了克隆。但是元素没有进行克隆。也就是浅拷贝,在平时使用的时候如果想要元素也进行复制的话,需要手动进行深拷贝。
9.contains(Object o)
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
int index = 0;
if (o == null) { // 如果o是null,那么只要从头开头遍历是否有null元素就可以了
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) // o不为null,要通过o的equals方法来判断是否存在这个元素。
return index;
index++;
}
}
return -1; // 找不到返回索引为-1
}
判断方法是否包含某个元素。通过indexOf方法判断是否存在查找元素的索引来实现。indexOf方法的代码如上。
10. descendingIterator()
public Iterator<E> descendingIterator() {
return new DescendingIterator();
}
private class DescendingIterator implements Iterator<E> {
private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}
}
提供逆序遍历的Iterator。如上代码所示,正序遍历元素的时候通过ListItr的next方法,DescendingIterator的next方法是ListItr的previous方法。
11. element()
public E element() {
return getFirst();
}
只是返回第一个元素,不会将第一个元素从LinkedList中删除。如果LinkedList为empty(first元素是null)会抛出NoSuchElementException。
12. get()
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
获取对应节点的元素,首先校验获取的节点是否合法。如果合法,通过node方法检索取出对应的节点元素。
13. getFirst()
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
等同于element方法。
14. getLast()
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
获取LinkedList尾节点元素,如果
15. indexOf(Object o)
代码见上面,indexOf就是找到索引元素第一次出现在LinkedList中的位置。如果没有找到返回-1。
16. lastIndexOf(Object o)
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
返回索引元素最后一次出现在LinkedList中的位置。如果没有找到返回-1。和indexOf相反的是从最后一个元素开始查找。
17.offer(E e)
public boolean offer(E e) {
return add(e);
}
将元素e添加到LinkedList的末尾。等同于调用add方法。
18. offerFirst(E e)
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
在LinkedList头部添加元素。等同于调用addFirst方法。
19. offerLast(E e)
public boolean offerLast(E e) {
addLast(e);
return true;
}
再LinkedList的尾部添加元素。等同于调用addLast方法。因为addLast方法等同于add方法,add方法等同于offer方法,所以offerLast等同于offer方法。
20. peek()
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
返回第一个元素,但是不会从LinkedList里面将他移除。如果LinkedList为empty,返回null。
21. peekFirst()
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
22. peekLast()
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
返回LinkedList中的最后一个元素。如果LinkedList为empty,返回null。
23. poll()
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next; // 将first节点置为next节点。
if (next == null)
last = null;
else
next.prev = null; // next节点的前置节点置为null。
size--; // size减一
modCount++; // 操作数加一
return element;
}
poll方法会返回并将第一个元素从LinkedList中删除。
24. pollFirst()
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
pollFirst逻辑上等同于poll方法。
25. pollLast()
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev; // 将last的prev节点赋给last
if (prev == null)
first = null;
else
prev.next = null; // 将last的prev节点的后置节点变为null
size--; // size减一
modCount++; // 操作数加一
return element;
}
pollLast方法会返回并将最后一个元素从LinkedList中删除。
26. pop()
public E pop() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
功能等价于平时使用的堆栈的pop,将栈顶(LinkedList)的最上面的元素返回并从堆栈(LinkedList)中删除。逻辑上等价于poll,本质上是调用了removeFirst方法。如果是LinkedList是empty,会抛出NoSuchElementException异常。
27. push()
public void push(E e) {
addFirst(e);
}
对应堆栈的push方法。将新元素压入栈顶。本质上是调用了addFirst方法。
28. remove()
public E remove() {
return removeFirst();
}
类似pop,poll方法返回第一个元素,同时将第一个元素从LinkedList中删除。
29. remove(int index)
public E remove(int index) {
checkElementIndex(index); // 检查index是否合法
return unlink(node(index)); // 将index处节点从LinkedList中删除
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next; // 将当前节点x的前置节点的后置指针变为next。这样就将x从节点中移除,将x的prev和next节点关联起来。
x.prev = null; // x的前置节点变为null
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null; // 帮助gc,删除x节点元素
size--;
modCount++;
return element;
}
在特定位置移除元素。
30. remove(Object o)
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
将第一个出现的元素o从LinkedList中移除。
31.removeFirst()
代码见pop方法。将LinkedList中第一个元素移除。
32.removeLast()
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev; // 将last节点置为l节点的前置节点
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
将最后一个元素从LinkedList中移除。
33. removeFirstOccurrence(Object o)
public boolean removeFirstOccurrence(Object o) {
return remove(o);
}
又是一个相同的方法,可能是为了让语义上更容易理解吧。调用的是remove(Object o)方法。将第一次出现的特定元素从LinkedList中删除。
34. removeLastOccurrence(Object o)
public boolean removeLastOccurrence(Object o) {
if (o == null) { // 如果为null ,直接查找最后出现的null元素
for (Node<E> x = last; x != null; x = x.prev) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
将最后出现的元素从LinkedList中删除。
35. set(int index, E element)
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
检查index是否和发,通过node方法找出对应节点。将节点的元素置换为新值。
36. toArray()
public Object[] toArray() {
Object[] result = new Object[size]; // 内部创建一个数组result
int i = 0;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item; // 将所有元素加到result内
return result;
}
将LinkedList的数据转化为Array类型。方法的时间复杂度和空间复杂度都是O(n)级别的。
37. toArray(T[] a)
public <T> T[] toArray(T[] a) {
if (a.length < size)
a = (T[])java.lang.reflect.Array.newInstance(
a.getClass().getComponentType(), size); // a的空间不够就创建一个新数组
int i = 0;
Object[] result = a;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item; // 添加元素
if (a.length > size) // a的空间超过LinkedList的size就将size处元素置为null
a[size] = null;
return a;
}
将LinkedList的元素替换到传入的数组a中。
总结:
了解了LinkedList,很多地方以后不能瞎用。最后的toArray方法中Array.newInstance以前都不知道,有时间好好研究下。下次介绍Vector类。