数据科学之数据可视化
一、 为什么数据可视化很重要
在数据科学有了结论或者结果后,我们还需要用一种容易理解,交流的方式把结果呈现给其他人,让我们的数据结论产生价值。其中重要的方式就是数据可视化。
二、 数据可视化的目的和方法
可视化的目的是帮助读者快速理解数据,比如趋势、相关性等。理想情况下,读者应该能在5~6秒之内完成一张可视化图表的分析。因此,我们需要认真对待可视化,确保可视化有效传达了信息。我们将重点介绍以下5类基本图表:散点图、折线图、条形图、直方图和箱形图。
三 可视化图表
3.1 散点图(scatter plots)
散点图是最容易制作的图形之一,它有两个数轴,每个数据点表示一个观测对象。散点图能体现变量间的相关性,适用于具有高相关性的变量。
假设我们有两个变量:平均每天看电视的时长和工作表现(0表示很差,100表示卓越)。我们想找出看电视时长和工作表现之间的关系。我们假设进行了一次调查问题卷,下面是对应的数据,和生成散点图的代码。
import pandas as pd
import matplotlib.pyplot as plt
# 调研问卷 14个人每周看电视时间小时数据
hours_tv_watched = [0, 0, 0, 1, 1.3, 1.4, 2, 2.1, 2.6, 3.2, 4.1, 4.4, 4, 4.5]
# 调研问卷 14个人每周工作绩效数据,最低0分,最高100分
work_performance = [87, 89, 92, 90, 82, 80, 77, 80, 76, 85, 80, 75, 73, 72]
# 创建DataFrame
df = pd.DataFrame({'hours_tv_watched': hours_tv_watched,
'work_performance': work_performance})
df.plot(x='hours_tv_watched', y='work_performance',
kind='scatter', ylim=(70, 100), xlim=(-1, 5))
plt.show()
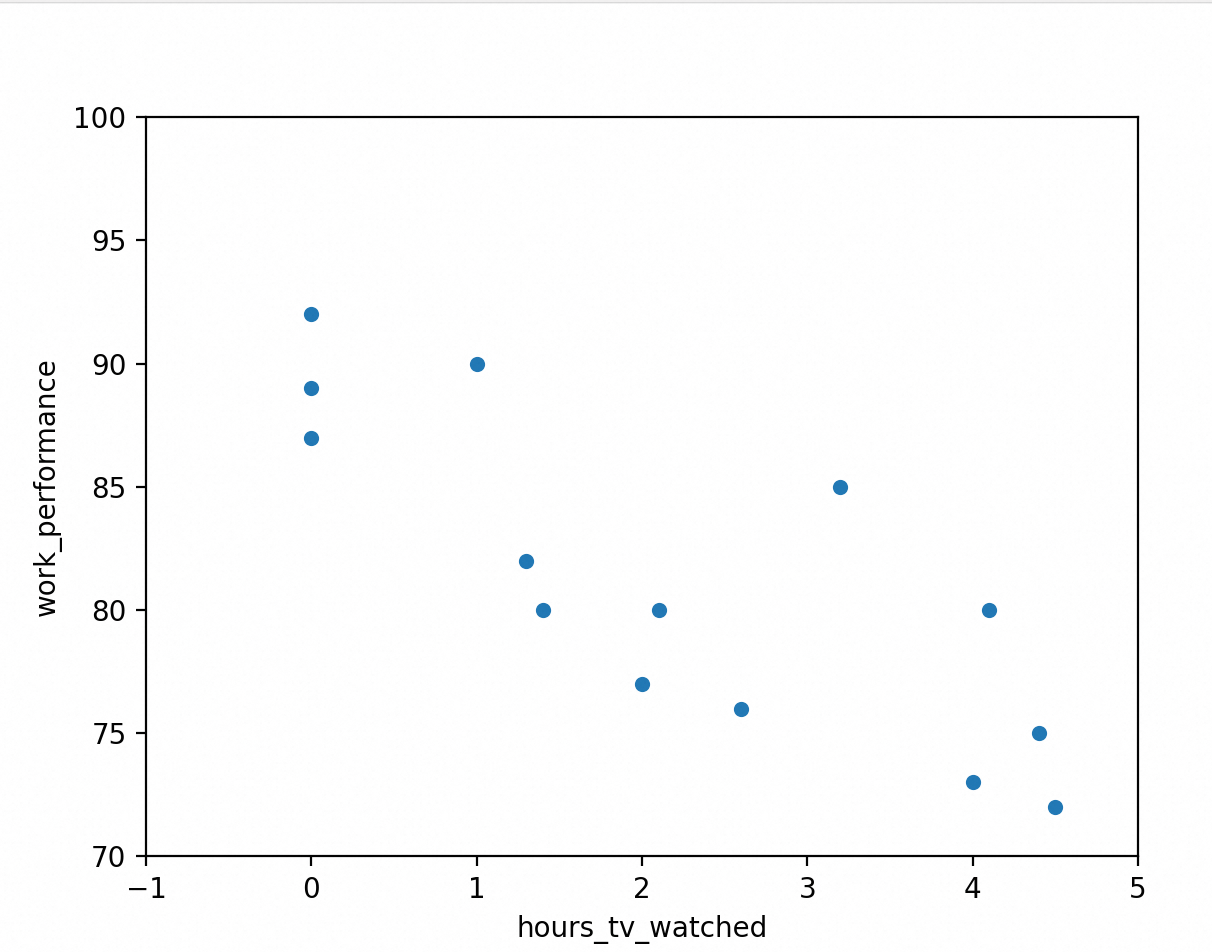
散点图中的每个点表示一个观测对象(本例中指被访问者),点的位置是观测对象在每个变量上所处的相对位置。从图中可以观察出变量间的关系:平均每天看电视时间越长,工作表现越差。当然我们知道这种简单分析得出的结论只能代表相关性,没办法具有因果性。我们不能由于盲目相信相关性而得出错误的分析结果。
3.2 折线图(line graphs)
折线图是应用最广泛的图形之一。折线图用线连接数据点,横轴通常是时间。折线图是展示变量随时间变化的最好方式之一。折线图和散点图一样,适用于定量类型的变量。
下面是一个随机的数据集合,模拟月份和销售额之间的变化关系的代码。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 创建时间序列:2025年1月到5月的第一个天
dates = pd.date_range(start='2025-01-01', periods=10, freq='MS')
# 随机生成销售额数据(例如在 150 到 300 之间)
sales = np.random.randint(150, 300, size=len(dates))
# 创建 DataFrame
df = pd.DataFrame({
'Date': dates,
'Sales': sales
})
# 设置“日期”列为索引
df.set_index('Date', inplace=True)
# 绘制折线图
plt.figure(figsize=(10, 6))
plt.plot(df.index, df['Sales'], marker='o',
linestyle='-', color='b', label='Sales')
# 添加标题和坐标轴标签(英文)
plt.title('Monthly Sales Trend')
plt.xlabel('Date')
plt.ylabel('Sales (USD)')
# 显示网格和图例
plt.grid(True)
# 显示图表
plt.show()
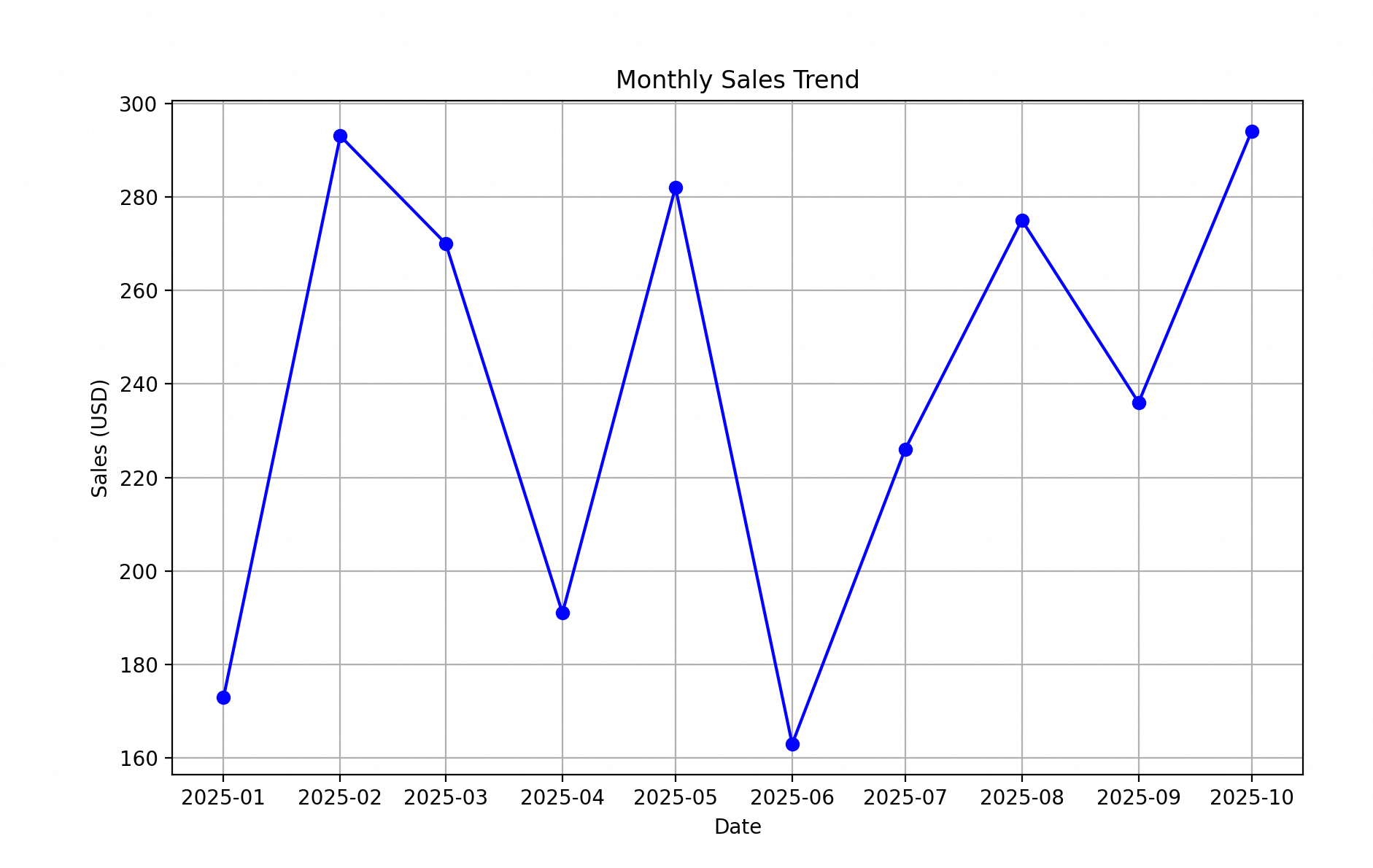
3.3 条形图(bar charts)
条形图用于对比不同的数据组。比如,我们可以用条形图对比各大洲的国家/地区数量。需要注意,在条形图中,x轴不再是定量变量,而(通常)是分类变量,y轴则依然是定量变量。
import matplotlib.pyplot as plt
import pandas as pd
drinks = pd.read_csv(
'/Users/zzx/python_project/pytorch_learning/python_workspace/data_science/data/drinks.csv')
# 对continent列进行计数 并绘制柱状图
drinks.continent.value_counts().plot(kind='bar', title='Continent Distribution')
plt.xlabel('Continent')
plt.ylabel('Number of Countries')
plt.show()
各大洲的国家/地区数量。每个柱子的下面有洲名的缩写,柱子的高度表示该大洲的国家/地区数量。我们可以很明显地看出非洲(AF)所含的国家/地区数量最多,南美洲(SA)所含国家/地区数量最少。

对各大洲数据计算平均值后,可以看到各大洲人均消耗酒精量。
drinks.groupby('continent').beer_servings.mean().plot(kind='bar')
plt.show()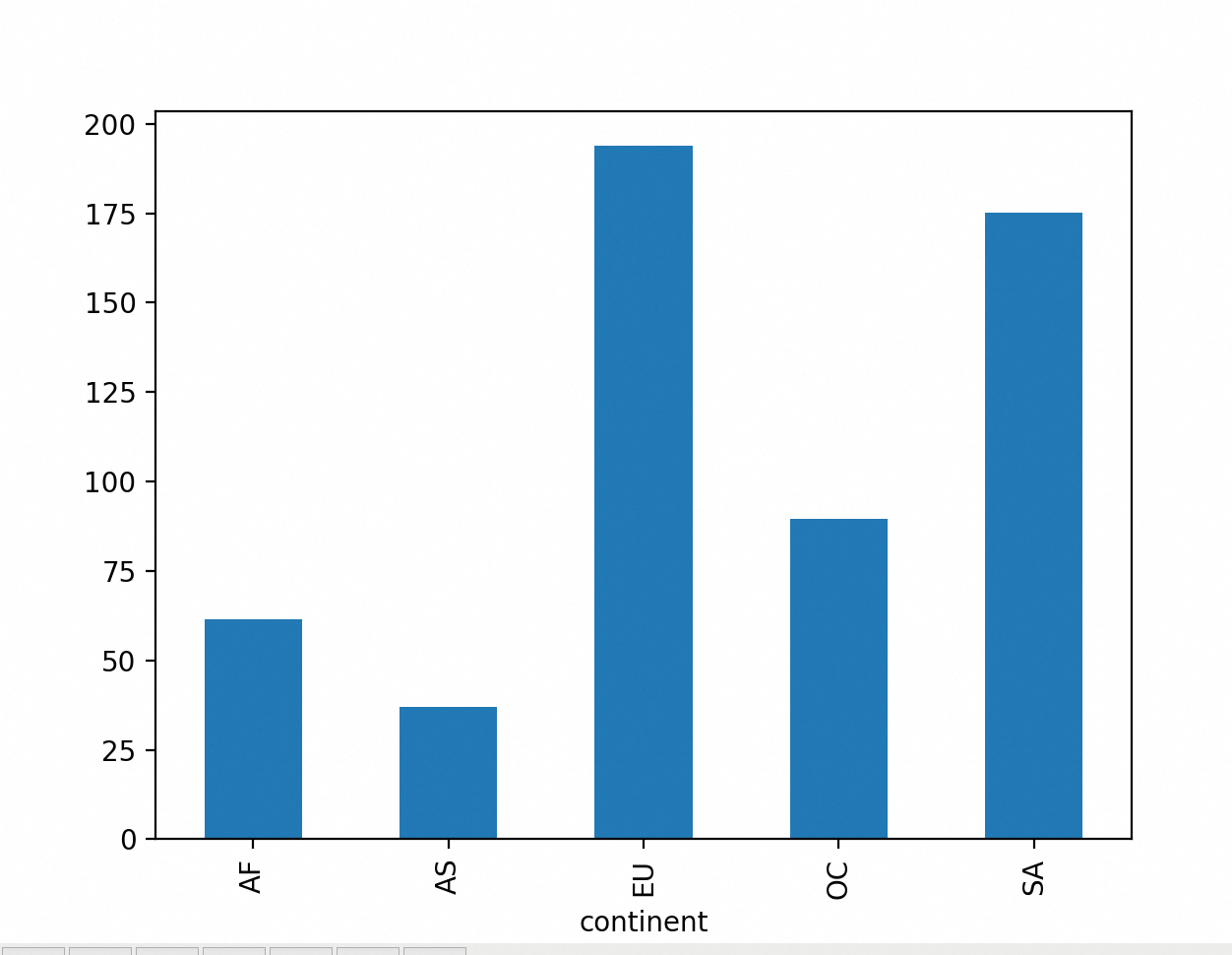
3.4 直方图(histogram)
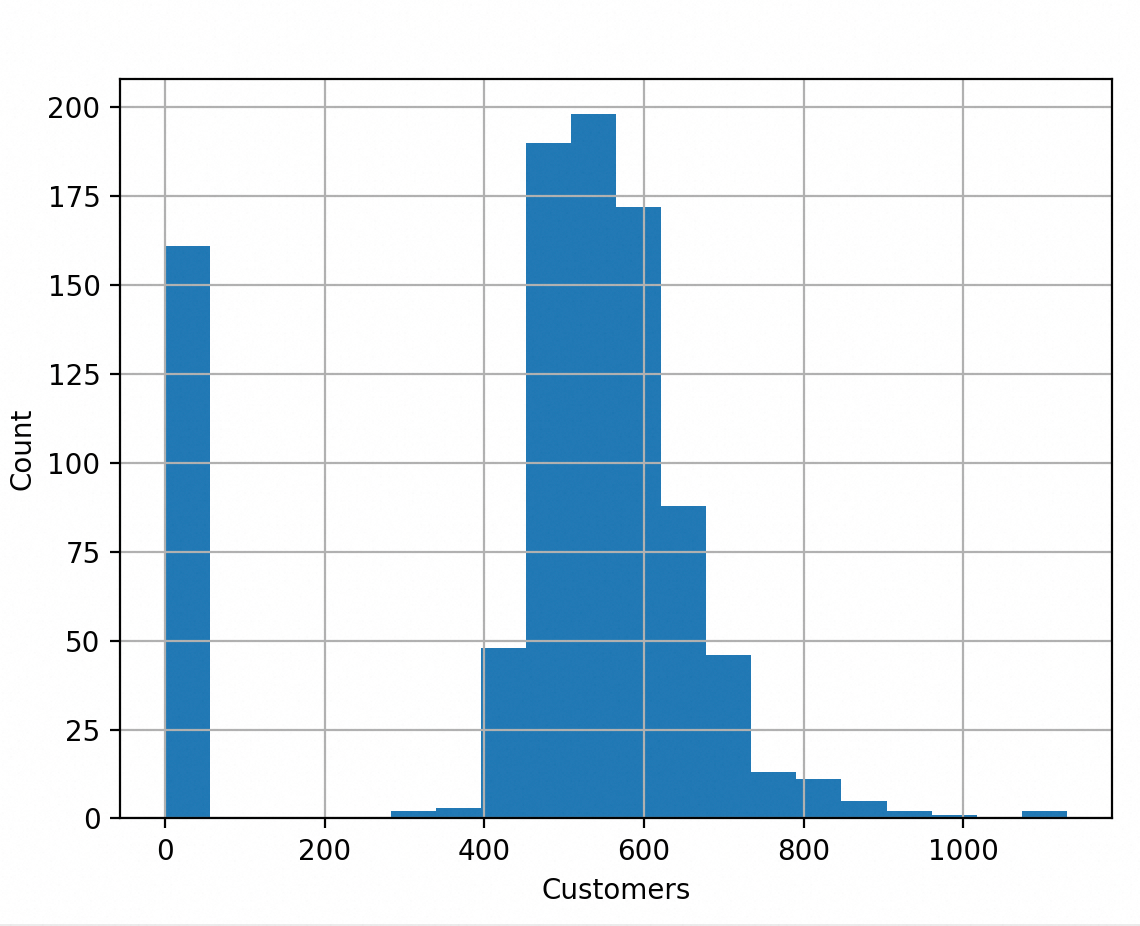
通常用来表示定量变量被拆分为等距数据桶(bin)后的频率分布,柱子的高度表示数据桶含有的元素数量。直方图看起来非常像条形图,它的x轴表示数据桶,y轴表示数量。
import pandas as pd
import matplotlib.pyplot as plt
rossmann_sales = pd.read_csv(
'/Users/zzx/python_project/pytorch_learning/python_workspace/data_science/data/rossmann.csv')
# rossmann_sales.head()
# 筛选第一个商店的销量
first_rossmann_sales = rossmann_sales[rossmann_sales['Store'] == 1]
# print(first_rossmann_sales)
# 绘制第一个商店的顾客分布
first_rossmann_sales['Customers'].hist(bins=20)
plt.xlabel('Customers')
plt.ylabel('Count')
plt.show()
每个类别表示一个数值区间,比如客户数介于600~620的区间。y轴和条形图类似,是每个类别对应的观测对象数量。从图可以看出,大多数时候,每天的客户数介于500~700。
3.5 箱形图(box plots)
箱形图通常用于表示变量值的分布情况。制作箱形图需要计算以下5个指标:
- 最小值;
- 第1个四分位(将样本中处于最低的25%区间的值和其他值隔开的值);
- 中位数;
- 第3个四分位(将样本中处于最高的25%区间的值和其他值隔开的值);
- 最大值。
在Pandas中,箱形图中的绿线表示中位数,箱子最上面和最下面的线分别是第3个四分位和第1个四分位。
import pandas as pd
import matplotlib.pyplot as plt
drinks = pd.read_csv(
'/Users/zzx/python_project/pytorch_learning/python_workspace/data_science/data/drinks.csv')
drinks.boxplot(column='beer_servings', by='continent')
plt.show()
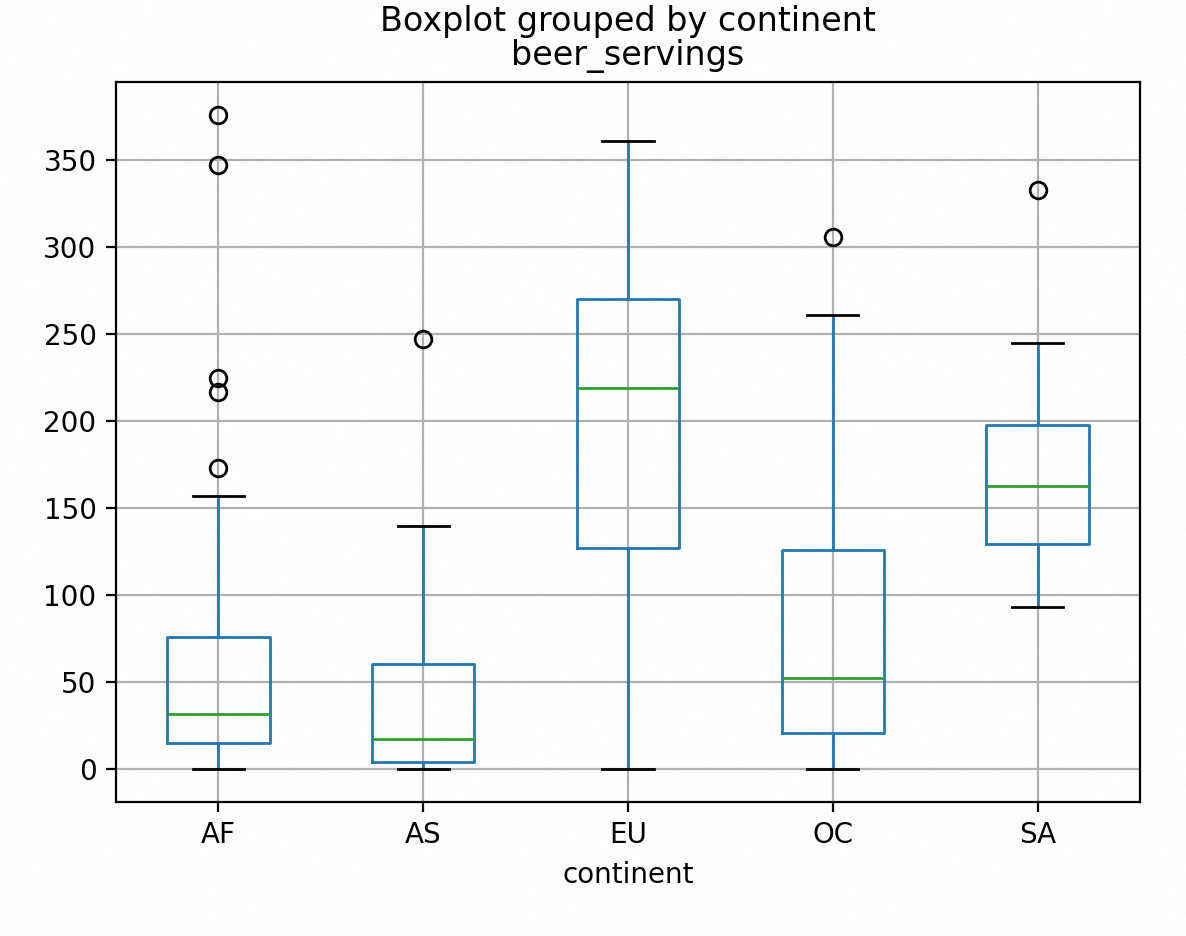
箱形图的另一种用途是发现离群值,它比直方图还要直观,因为箱形图包含了最大值和最小值。
下面是门店顾客数据集的箱形图
first_rossmann_sales.boxplot(column='Customers', vert=False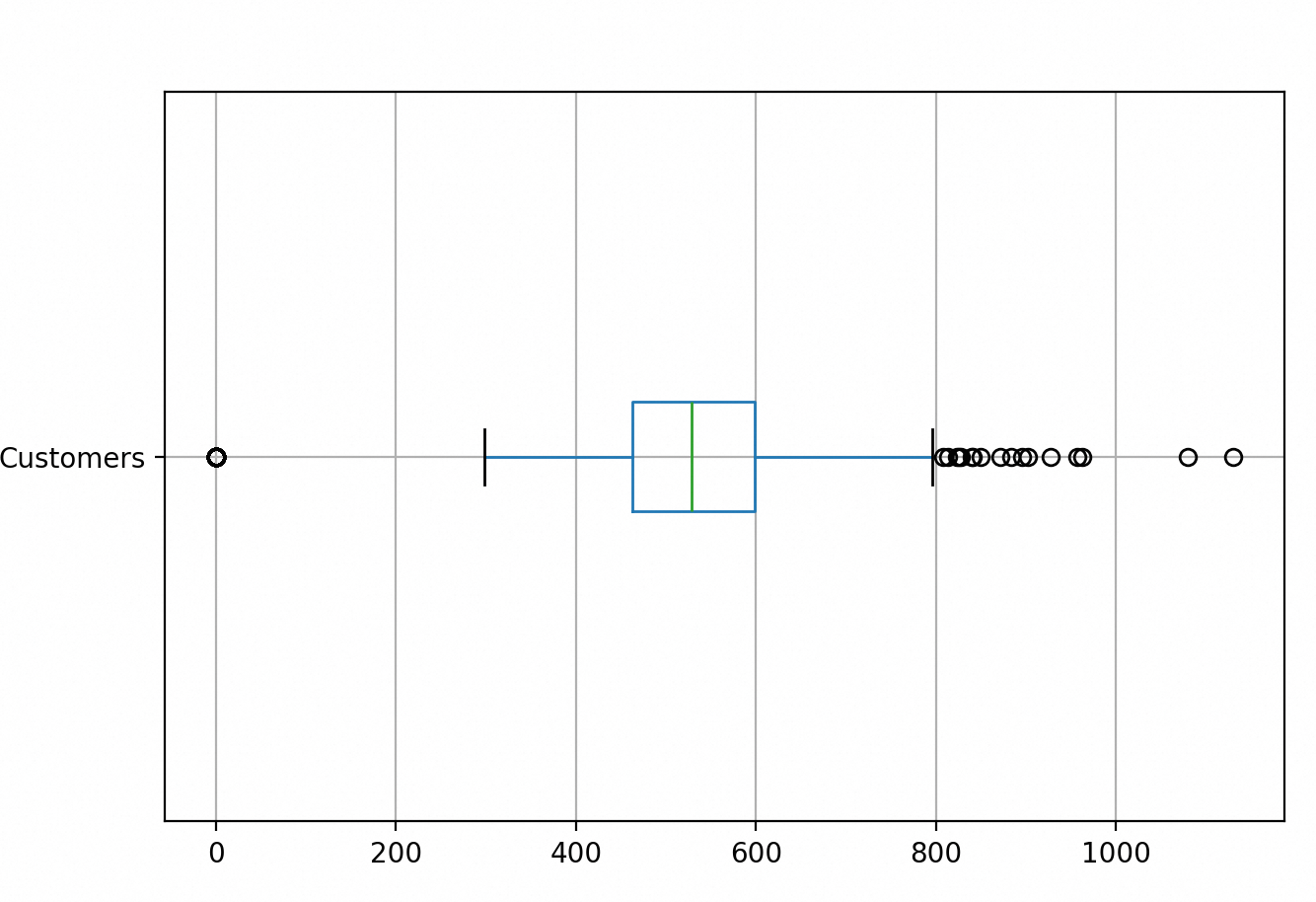
可以通过describe函数查看类似的数据
print(first_rossmann_sales['Customers'].describe())count 942.000000
mean 467.646497
std 228.930850
min 0.000000
25% 463.000000
50% 529.000000
75% 598.750000
max 1130.000000四 总结
数据可视化是数据科学的关键环节,能将复杂数据转化为可视化的方式让结论容易理解。选择合适工具和图表类型,遵循设计规范,可显著提升分析效率和沟通效果。上面是常见的统计图表和python的实现方式。
ref:
- 《深入学习数据科学》 [美] 斯楠·奥兹德米尔(Sinan Ozdemir)著
2. 代码和数据参考:https://github.com/PacktPublishing/Principles-of-Data-Science-Third-Edition